
TF-IDF
Il TF-IDF è un algoritmo di estrazione delle informazioni testuali da una base dati. Nel campo della IR ( Information Retrieval ) è utilizzato come metodo di ricerca nei database di grandi dimensioni e nei search engine sul web.
Il nome dell'algoritmo è composto da due termini: TF e IDF. Il termine TF è l'acronimo di Term Frequency ( frequenza del termine ) mentre IDF è l'acronimo di Inverse Document Frequency ( frequenza inversa nei documenti ).
Il metodo viene ideato nel 1972 da S. Jones, il quale definisce una prima formula IDF. Successivamente, l'algoritmo viene perfezionato nel 1975 da Salton con l'aggiunta della componente TF.
Come funziona l'algoritmo
Dati N documenti in una base dati, si decide un termine K da ricercare. Secondo Jones, l'efficacia del processo di estrapolazione è inversamente proporzionale alla distribuzione omogenea del termine nei documenti.
Se il termine K è presente in tutti gli N documenti della base dati, l'efficacia del processo di ricerca è bassa, in quanto la parola K è comune in tutte le risorse ( es. articoli, preposizioni, ecc. ).
Viceversa, se il termine K è contenuto soltanto in pochi documenti, l'efficacia della selezione diventa più elevata. Il processo di searching restituisce le poche pagine che contengono il termine.
Il calcolo di IDF ( Inverse Document Frequency )
Questa parte dell'algoritmo riguarda la componente IDF ( Inverse Document Frequency ), che può essere sintetizzata con la seguente formula:
IDF = log N / nk
Ad esempio, il termine K è presente in tre documenti ( nk=3 ) su cento documenti ( N=100 ). Il valore di IDF è pari a 1.5.
Se il termine K fosse contenuto in tutti i documenti della banca dati ( nk=100 ) il valore di IDF diventerebbe pari a zero ( LOG 1 = 0 ). Questo permette di eliminare le parole comuni dal processo di ricerca.
Questa è soltanto la prima parte dell'algoritmo, quella ideata da Jones nel 1972. Alla componente IDF si deve aggiungere quella TF.
Il calcolo di TF ( Term Frequency )
Con TF si intende la frequenza del termine in un documento ( Term Frequency ). Questa componente è stata aggiunta da Salton nel 1975 per perfezionare l'algoritmo IDF di Jones.
Il valore di TF è determinato dal rapporto tra il numero di occorrenze OK,X del termine K nel documento X e il numero DX delle parole del documento X ( dimensione del documento ).
TF = OK,X / DX
Ad esempio, il termine K si presenta 10 volte nel documento X ( Ok,x=10) e il documento è composto da 100 parole ( Dx=100). Il valore TF del termine K nel documento X è pari a 0,10.
Il calcolo di TF-IDF
Per calcolare il TF-IDF è sufficiente moltiplicare tra loro il valore TF e IDF come nella seguente :
TF-IDF = TFK,X · IDFK
Nell'esempio precedente il valore di TFk,x è uguale a 0,10 mentre quello di IDFk è uguale a 1,5. L'indicatore TF-IDF è pertanto pari a 0,15.
I vantaggi dell'algoritmo TF-IDF
Il parametro TF-IDF è elevato quando la parola è molto frequente in un documento e il termine non è presente su tutti i documenti della banca dati. Questo permette di ridurre l'importanza delle parole comuni ( es. "del", "della", "un", ecc. ) e valorizzare gli altri termini della query dell'utente.
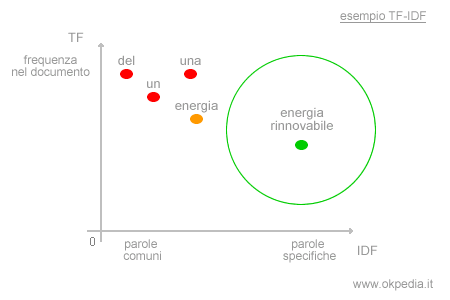
Ad esempio, in un motore di ricerca l'utente digita la query "una energia rinnovabile". In molti documenti i termini "una" e "energia" sono molto frequenti, in quanto sono parole comuni. Sono però informazioni poco rilevanti.
Il documento X contiene una discreta frequenza della parola "energia rinnovabile". Questa combinazione di termini ha un valore IDF molto più alto, si tratta di una parola specifica ( non comune ).
Pur avendo una frequenza TF inferiore rispetto alle altre parole comuni ( "energia", "una", ecc. ), la combinazione "energia rinnovabile" acquisisce un maggiore peso nella ricerca TF-IDF.
In conclusione
L'algoritmo TF-IDF associa maggiore importanza ai termini meno frequenti nel corpus del documento ma più rilevanti per la ricerca. Le parole comuni sono molto frequenti ma, essendo anche presenti in tutti i documenti, hanno una ridotta importanza nel processo di selezione delle risorse.



