
Metodo inferenziale del campionamento diretto
Il metodo inferenziale del campionamento è una tecnica informatica di inferenza logica approssimata. A partire da un sistema di conoscenza, il metodo assegna dei valori casuali alle variabili e registra i risultati finali. Nelle basi di conoscenza il metodo del campionamento è utilizzato per rispondere alle domande degli utenti.
Un esempio pratico
La seguente rete bayesiana mostra un sistema molto semplice, composto da 6 variabili ( O, T, B, U, G, I ). Le prime variabili hanno una probabilità semplice mentre le altre hanno una probabilità condizionata, ossia associata al risultato delle precedenti.
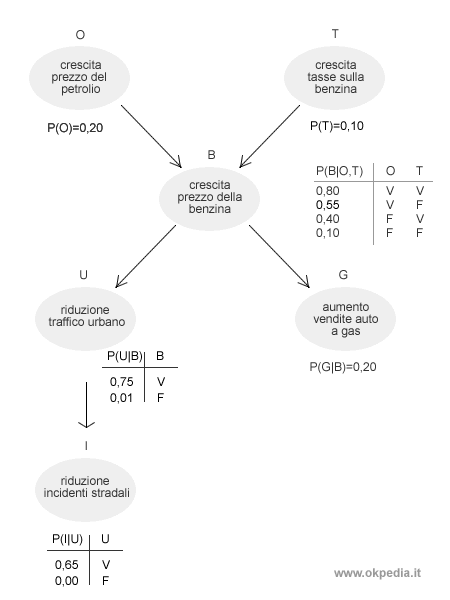
Chiediamo al sistema se gli incidenti stradali si ridurranno e con quale percentuale. Sappiamo che nel sistema questa ipotesi si verifica quando la variabile I è vera.
L'algoritmo inferenziale comincia con l'assegnare alle variabili dei valori casuali, entro il loro dominio di variazione, secondo la tecnica dell'inferenza approssimata.
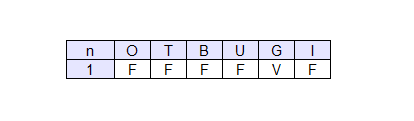
Al termine del primo ciclo di campionamento, l'algoritmo osserva quale risultato ha ottenuto sulla variabile del problema ( I ). In questo caso la variabile I ha valore False, quindi il numero degli incidenti non si riduce.
L'algoritmo provvede a compiere altri tre cicli di campionamento, sempre assegnando casualmente i valori alle variabili e registrando alla fine il risultato ottenuto sulla variabile I.
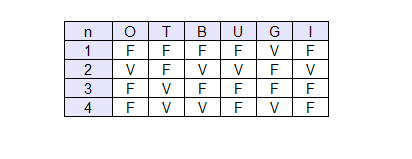
Al termine del quarto campionamento ( N=4 ) l'algoritmo inferenziale di campionamento conta quante volte la variabile I è vera ( IV=1 ). L'algoritmo può così rispondere alla domanda iniziale affermando che la probabilità della riduzione degli incidenti in futuro è del 25%.
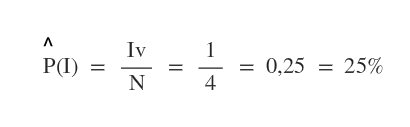
Si tratta di un esempio molto semplice, utile solo per esporre meglio la tecnica. Il problema dell'esempio è facilmente risolvibile anche con un'enumerazione completa. Il vantaggio del metodo del campionamento si ottiene quando il problema è molto complesso, composto da migliaia di variabili.
Quanti campionamenti sono necessari?
Non esiste un numero predefinito di campionamenti. Secondo un principio generale, tendendo il numero dei campionamenti ( N ) a infinito, la probabilità ottenuta Iv/N si avvicina a quella reale P(Iv).
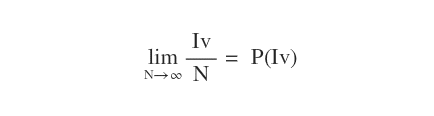
In altri termini, quante più iterazioni di campionamento sono eseguite, tanto più la media finale sarà realistica.
Ovviamente, al crescere delle iterazioni aumenta anche la complessità temporale dell'algoritmo, ossia il tempo di esecuzione dell'elaborazione dei dati.
Le query condizionate
Il metodo del campionamento è utilizzato anche per rispondere alle query condizionate, ossia alle domanda in cui la variabile da studiare è condizionata a un'ipotesi iniziale.
Ad esempio, se aumenta il prezzo del petrolio, in che percentuale potrebbero ridursi gli incidenti stradali?
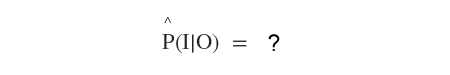
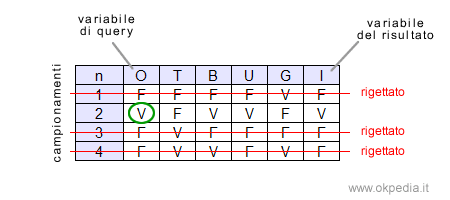
Per rispondere a questa domanda l'algoritmo prende in considerazione solo il campionamento in cui la variabile O è Vera ( aumenta il prezzo del petrolio ), rigettando tutti gli altri. Questa tecnica è detta campionamento di rigetto ( rejection sampling ).
Così facendo, però, molti campionamenti diventano inutili. Ad esempio, nel caso precedente soltanto un campionamento è compatibile mentre gli altri tre sono rigettati.
Riducendosi il numero dei campioni ( N=1 ) anche la stima finale perde di consistenza. Essendoci un solo caso in cui O e I sono veri, si potrebbe pensare che al 100% si riducono gli incidenti stradali.
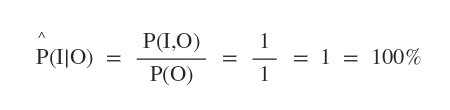
Per risolvere questo problema si possono percorrere due strade alternative:
- Numero dei campionamenti. Si aumenta il numero dei campionamenti ( N ) per incrementare i casi in cui la variabile della condizione iniziale è soddisfatta. Ad esempio, si passa da quattro a otto campionamenti ( N=8 ). È la strada meno efficiente, poiché non esclude i campionamenti rigettati e aumenta il tempo di elaborazione.
- Selezione ex-ante dei casi consistenti. Si seleziona un campione di casi in cui la condizione iniziale è soddisfatta ( O=Vero ) e si effettua soltanto su questi il campionamento casuale su tutte le altre variabili. In alternativa, si impone alla variabile della condizione un valore costante uguale alla condizione da rispettare ( O=Vero ). È la strada più efficiente.
Questa tecnica è conosciuta come likelihood weighting ( pesatura di verosimiglianza ).
La likelihood weighting
Seguendo la tecnica likelihood weighting tutti gli eventi devono essere consistenti con la condizione iniziale ( es. O=Vero ).
Mantenendo immutato il numero dei campionamenti ( N=4 ) si riesce a ottenere una stima probabilistica più attendibile sul risultato finale.
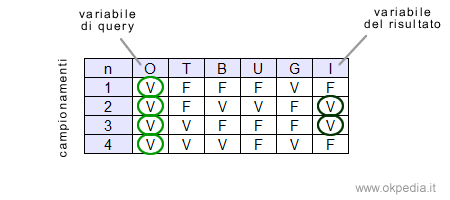
In questo caso, su N=4 campionamenti consistenti con la condizione iniziale O=Vero, si verificano due casi in cui la variabile V è vera. L'algoritmo può così rispondere alla domanda affermando che il numero degli incidenti si riduce (I=Vera) nel 50% dei casi quando il prezzo del petrolio aumenta.
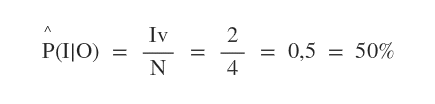
Anche in questo caso si tratta di una stima approssimata, calcolata facendo riferimento all'osservazione diretta della realtà. Non ci sono campionature rigettate ex-post bensì ex-ante.



