
Inferenza approssimata
L'inferenza approssimata è una tecnica inferenziale non completa, in cui il processo di ragionamento logico non esplora tutti gli stati di un problema ma soltanto una parte di essi. È utilizzata nel campo dell'intelligenza artificiale per realizzare gli algoritmi di inferenza logica.
Quali sono le caratteristiche
L'inferenza approssimata viene realizzata mediante l'assegnazione casuale dei valori a tutte le variabili o soltanto a una parte di esse. La randomizzazione è una caratteristica che accomuna tutti gli algoritmi di questo tipo, conosciuti anche come algoritmi Monte Carlo.
Esistono diversi metodi per realizzare un ragionamento inferenziale approssimativo. Uno dei più semplici è il metodo del campionamento.
Alla variabile viene assegnato uno dei valori possibili del suo dominio, tenendo conto sia della distribuzione probabilistica dei valori ( probabilità semplice ) che, eventualmente, delle variabili determinanti ( probabilità condizionate ).
Ad esempio, in una rete bayesiana sono assegnati i valori ai nodi iniziali tenendo conto della loro distribuzione probabilistica semplice. Se una variabile è vera al 10% e falsa al 90% anche l'assegnazione random rispetterà questa distribuzione.
In base al valore assegnato alle prime variabili ( nodi genitori ) si assegna casualmente anche il valore alle variabili successive ( nodi figli ) secondo la loro distribuzione probabilistica condizionata.
Un esempio pratico di inferenza approssimata
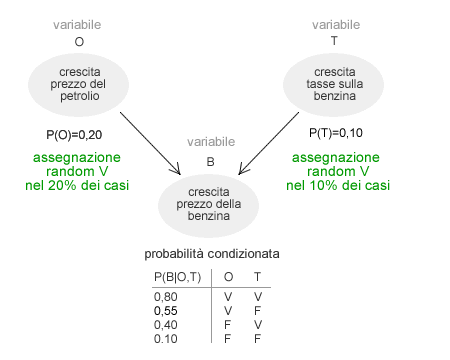
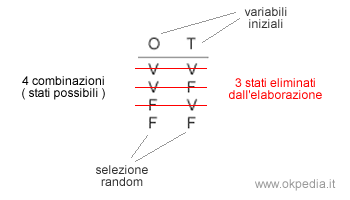
La seguente rete bayesiana mostra le relazioni tra le variabili di un sistema. Quelle più in alto sono i nodi determinanti. Per verificare tutte le combinazioni di valori del problema sono necessarie 32 iterazioni ( 25 ). L'inferenza approssimata però non le analizza tutte.
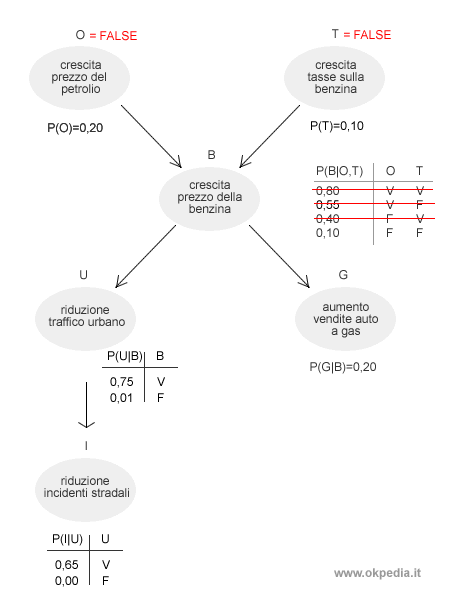
Le prime variabili del problema O e T hanno una probabilità semplice di verificarsi rispettivamente del 20% ( 0,20 ) e del 10% ( 0,10 ). Ipotizziamo che il processo di assegnazione casuale restituisca il valore "falso" sia alla variabile O che alla variabile T.
In questo modo l'algoritmo esclude dal computo gli altri casi meno probabili. Così facendo, ha ridotto l'enumerazione delle prime variabili ( O, T ) da quattro combinazioni a una sola. Le altre combinazioni di valori sono escluse dall'elaborazione.
A sua volta, la variabile B della rete dipende dal valore delle precedenti ( O, T ) a cui precedentemente l'algoritmo ha assegnato il valore false in modo random. Pertanto, la variabile B ha una probabilità condizionata P(B|O,T) pari al 10% (0,10).
L'algoritmo inferenziale approssimativo assegna alla variabile B un valore casuale che nel 10% dei casi sarà true e nel 90% dei casi sarà false. È quindi molto probabile che alla variabile B sia assegnato il valore false.
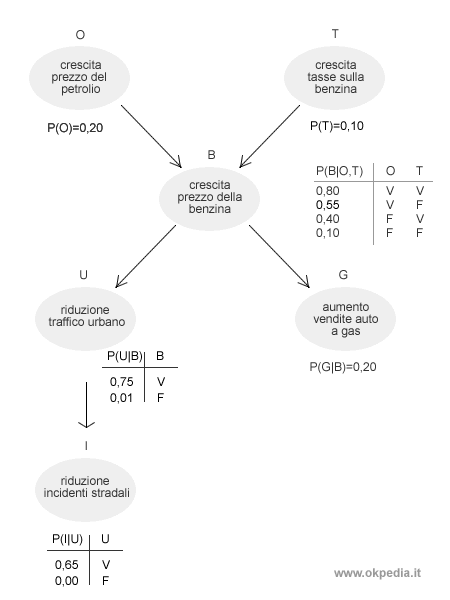
L'enumerazione random procede verso il basso assegnando i valori alle restanti variabili U e G, entrambi dipendenti dal valore della variabile B ( false ). E così via fino al completamento di tutte le variabili.
Qual è il vantaggio dell'inferenza approssimata
L'inferenza approssimata ha il vantaggio di ridurre la complessità computazionale nel problem solving. Non restituisce la soluzione ottimale ( migliore risposta ) ma una soluzione probabilmente accettabile ( sub-ottimale ) nel minore tempo possibile.
Uno dei principali vantaggi è, quindi, la velocità della risposta. Si presta ad essere utilizzata nei problemi in cui il tempo è fondamentale, nelle decisioni rapide.
Un altro vantaggio è nella memoria necessaria per affrontare un problema. Non dovendo elaborare tutti gli stati, necessita di uno spazio di memoria inferiore rispetto agli algoritmi ad enumerazione completa.
L'inferenza approssimata si presta ad essere utilizzata anche nei problemi che non possono essere analizzati in modo completo perché troppo complessi ( NP-difficili ).
La differenza tra l'inferenza completa e approssimata
Nell'inferenza completa l'algoritmo analizza tutte le possibili situazioni prima di giungere al risultato finale ( enumerazione esatta ). Una volta trovato, il risultato è certamente il migliore possibile ( soluzione ottimale ). Tuttavia, questo implica un grande consumo di memoria e di tempo di elaborazione.
Inoltre, alcuni problemi non possono essere affrontati in modo completo ed esaustivo, per la loro stessa natura. A volte non basterebbe nemmeno una memoria informatica grande come l'Universo per risolvere un problema molto complesso.

Gli algoritmi inferenziali approssimativi, invece, non esplorano tutte le possibilità del problema ma soltanto una parte ( non completezza ) ma restituiscono in tempi più rapidi una soluzione sub-ottimale.
La complessità spaziale e temporale dell'algoritmo si riduce notevolmente con l'inferenza approssimata, anche se l'ottimalità della risposta non è più garantita con certezza.



