
Algoritmo del Semantic Flux
Il Semantic Flux è un algoritmo dei motori di ricerca ed è classificato tra i filtri. L'algoritmo ha lo scopo di ridurre la presenza dei contenuti simili sulle pagine dei risultati di ricerca del search engine. È utilizzato per individuare documenti semanticamente simili su siti web differenti e filtrare quelli simili.
Quando l'algoritmo individua due o più pagine semanticamente simili, ne seleziona una ed esclude tutte le altre. Pur essendo scritti in modo diverso, i documenti esclusi sono considerati contenuti duplicati che non arricchiscono i risultati del motore di ricerca.
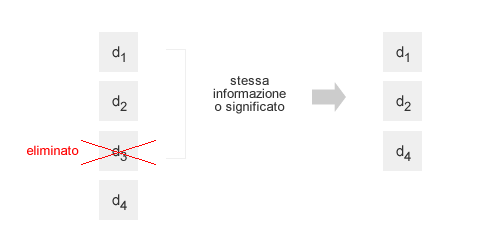
I documenti semanticamente simili
La presenza dei documenti semanticamente uguali o simili riduce la qualità dei risultati di ricerca. I documenti semanticamente simili sono contenuti scritti in modo diverso, hanno una propria sintassi, lessico e struttura. Tuttavia, offrono al lettore la medesima informazione, lo stesso significato, seppure scritto in modo diverso.
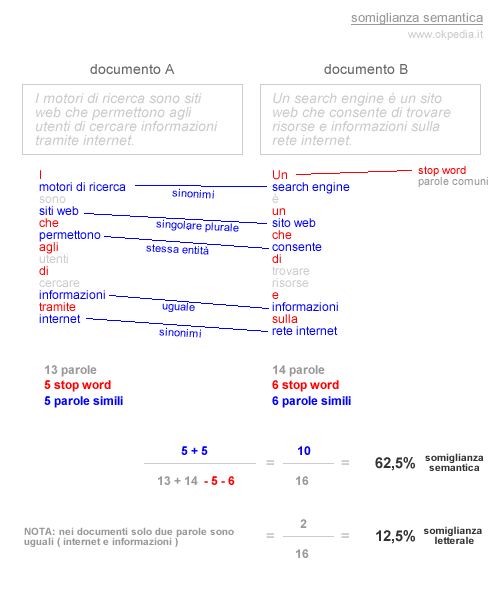
Nel seguente esempio sono mostrati due documenti che veicolano la stessa comunicazione in modo differente. I due documenti hanno una somiglianza letterale del 12,5% e una somiglianza semantica del 62,5%. Sono scritti in modo diverso ma dicono la stessa cosa. Sono un esempio di duplicazione semantica dei contenuti.
La qualità dei risultati di ricerca è fortemente legata a questo aspetto. I search engine più evoluti hanno imparato ad evitare questo problema, dando maggiore importanza alla content diversity, ossia alla diversità semantica dei contenuti da pubblicare nei risultati di ricerca.
Ad esempio, una pagina dei risultati è generalmente composta da dieci indirizzi URI. Se uno o due di questi presentano determinate informazioni, è inutile sprecare le altre otto posizioni per visualizzare altri siti che non aggiungono nuove informazioni.
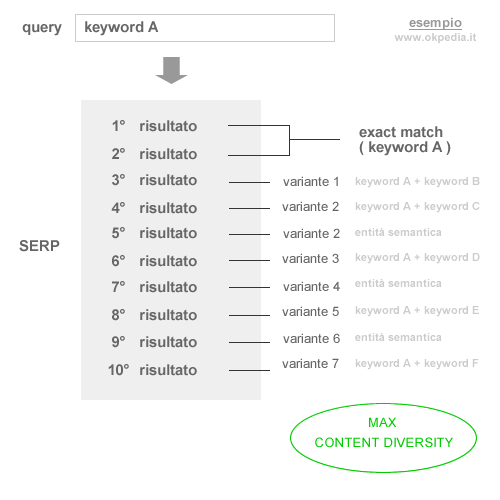
Generalmente, le prime posizioni sono occupate dai siti web con maggiore autorevolezza. Le posizioni secondarie sono invece utilizzate per inserire dei documenti con una variante di ricerca. In questo modo l'utente può cliccare su altri argomenti utili, non ridondanti, sullo stesso argomento di interesse.
La perdita di visibilità dei documenti simili
Il Semantic Flux non è una penalizzazione algoritmica bensì un algoritmo di filtro. I documenti filtrati non sono penalizzati o declassati. Ciò nonostante il risultato è uguale poiché i documenti filtrati perdono la visibilità nella prima pagina dei risultati, scendendo in seconda o terza pagina.
Questo filtro può anche colpire nomi di dominio e sottodomini appartenenti alla medesima proprietà. Quando un contenuto è presente su più siti di una stessa persona, soltanto un documento ottiene la visibilità sulle Serp, mentre gli altri sono filtrati dai risultati.
- La rielaborazione dei contenuti. In passato, le vecchie tecniche Seo di ottimizzazione on-page utilizzano la rielaborazione di un contenuto originale in molteplici versioni, ognuna con parole leggermente differenti, per aumentare il posizionamento del sito sul search engine su diverse parole chiave ( es. sinonimi ). Non si tratta di spam poiché i documenti appaiono differenti. Queste tecniche hanno prodotto una grande quantità di documenti con informazioni simili che, molto spesso, offrono all'utente la medesima informazione, seppure scritta in modo diverso.I documenti non sono uguali, hanno sintassi, lessico e strutture diverse, ma sono semanticamente uguali. Questo fenomeno è partcolarmente diffuso nelle news, dove molte notizie sono rielaborate dalla stessa fonte. Queste vecchie tecniche Seo non sono più efficaci per il posizionamento sui motori di ricerca. Gran parte di questi documenti duplicati sono ormai filtrati con l'evoluzione degli algoritmi dei search engine che ora non analizzano più le query soltanto sulla base delle keyword ma anche sulle entità semantiche.



