
Spider ( software bot o crawler )
Uno spider è un programma informatico automatico ( software bot ) utilizzato dai motori di ricerca per acquisire i dati dalla rete internet, al fine di poterli indicizzare nel proprio database. I motori di ricerca utilizzano i software spider per censire in modo automatico i contenuti del web, per trovare le nuove pagine e per acquisire le modifiche sulle pagine già indicizzate nel database del motore di ricerca. Questi software sono conosciuti come spider, bot, robot o crawler. I software spider hanno il compito di mappare il web seguendo i collegamenti ipertestuali ( link ) delle pagine web.
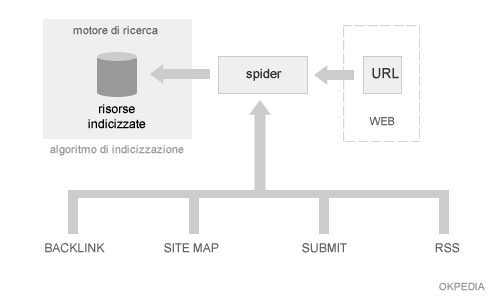
Gli spider possono leggere il documento html della pagina, acquisire e archiviare il contenuto testuale per indicizzarlo nel motore di ricerca. Un software spider riconosce i link in uscita di una pagina analizzando il codice Html e, infine, li seguono per espandere a rete l'acquisizione dei dati. Questo comportamento ricorda quello di un ragno quando costruisce una ragnatela, per questa ragione questi software sono conosciuti con il termine 'spider' ( ragno ).
 Generalmente lo spider non è un agente razionale, è un semplice programma che si limita ad eseguire una copia cache in formato testuale delle pagine ed eventualmente riconoscere poche altre informazioni come i link all'interno della pagina. L'analisi più approfondita della risorsa viene fatta successivamente da altri algoritmi del search engine ( es. algoritmi di indicizzazione ) che analizzano la copia cache della pagina direttamente sul database del search engine. È sempre il search engine a decidere la lista degli indirizzi URL ( indirizzi delle pagine web ) che il software spider deve visitare.
Generalmente lo spider non è un agente razionale, è un semplice programma che si limita ad eseguire una copia cache in formato testuale delle pagine ed eventualmente riconoscere poche altre informazioni come i link all'interno della pagina. L'analisi più approfondita della risorsa viene fatta successivamente da altri algoritmi del search engine ( es. algoritmi di indicizzazione ) che analizzano la copia cache della pagina direttamente sul database del search engine. È sempre il search engine a decidere la lista degli indirizzi URL ( indirizzi delle pagine web ) che il software spider deve visitare.



