Il processo di indicizzazione
L'indicizzazione è il processo di raccolta delle informazioni di una risorsa online e di inserimento nell'indice del database di un motore di ricerca. Si parla di indicizzazione nel caso dei search engine sul web, in ambito SEO, sia in quello dei motori di ricerca interni di un sistema chiuso.
Nella fase di indicizzazione ogni risorsa viene catalogata e associata a un insieme di parole chiave ( keyword ) che svolgono le funzioni tipiche degli indici e agevolano il successivo reperimento delle informazioni nel database.
L'indicizzazione segue la fase di raccolta dati tramite la quale il motore di ricerca riceve l'informazione sulla risorsa dall'esterno.
La fase della raccolta dei dati
La raccolta dati può avvenire tramite i seguenti modi;
- Spider ( bot ). Lo spider è un software agente automatico ( bot ) in grado di scandagliare la rete alla ricerca delle risorse. Sul web gli spider ottengono le informazioni sulle nuove risorse seguendo i collegamenti ipertestuali presenti nelle risorse già conosciute. Quando lo spider trova una nuova risorsa, effettua una copia del codice sorgente della stessa e segnala l'indirizzo al motore di ricerca per l'inserimento nell'indice. Gli algoritmi spider sono chiamati anche robot, bot o crawler.
- Submit ( segnalazione manuale ). La procedura di submit è effettuata dagli utenti esterni, i quali segnalano al motore di ricerca l'indirizzo di una nuova risorsa oppure quello di una risorsa non ancora presente nell'indice del search engine. Il submit è semplicemente una form con una casella di input. Gli indirizzi segnalati sono utilizzati dagli agenti spider per verificare l'esistenza delle risorse ed eventualmente procedere alla loro indicizzazione.
- Site map. La site map è la costruzione di un file contenente tutti gli indirizzi delle risorse di un sito web. È realizzata dai webmaster e dagli sviluppatori del sito web stesso, allo scopo di segnalare al motore di ricerca l'elenco completo degli indirizzi delle pagine di un sito senza doverli segnalare singolarmente con la procedura di submit. La site map sincrona consente la segnalazione in tempo reale delle nuove risorse e degli ultimi aggiornamenti alle risorse già esistenti.
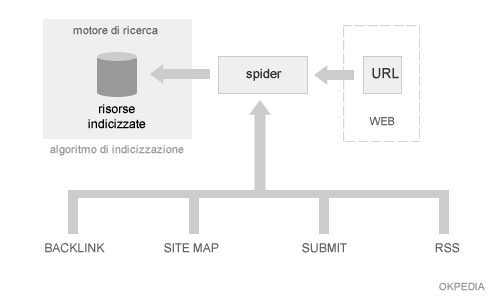
Gli spider del motore di ricerca possono ottenere informazioni sulle risorse in rete anche da altri canali secondari. Ad esempio, gli spider possono accedere alle risorse aggiornate analizzando i file RSS dei siti web oppure dai feedback provenienti da altri servizi offerti dal motore di ricerca ( es. script dei servizi di statistica online, pubblicità, posta elettronica, toolbar sul browser, ecc. ).
In alcuni casi lo spider torna a visitare periodicamente anche i nomi di dominio scaduti e gli URL delle pagine eliminate, per verificare il loro eventuale ritorno online.
La fase di scansione dei dati
Una volta ottenuta l'informazione sull'esistenza di una risorsa online, la raccolta online procede con la scansione delle informazioni contenute nella risorsa, tramite il passaggio dell'algoritmo di crawling.
Nella fase di scansione l'algoritmo crawler registra una copia cache del codice html della pagina e la archivia sui propri server per analizzare offline le informazioni contenute, in modo più approfondito, senza doverle leggere ogni volta online sulla risorsa.
In genere, sono archiviate soltanto le copie cache del codice html delle pagine web. In alcuni casi sono archiviati anche i files richiamati dalla pagina web, come i files delle immagini, i documenti in altro formato ( es. pdf ) e i file multimediali ( video, audio, ecc. ).
La fase di indicizzazione dei dati
Dopo aver ottenuto l'informazione sulla risorsa, nella fase di indicizzazione gli algoritmi del motore di ricerca la inseriscono nell'indice del database assegnandogli delle parole chiave ( keyword ) e un peso ( rank ) sulla base della sua importanza. Per scegliere le parole chiave e associare il ranking alla risorsa, l'algoritmo di indicizzazione analizza diversi fattori:
- Fattori interni. I fattori interni sono informazioni presenti all'interno della risorsa stessa. Ad esempio, i motori di ricerca di prima generazione associano un peso maggiore alle informazioni presenti in appositi tag del linguaggio HTML ( metatags, titoli, header, grassetto, ecc. ... ). Si tratta soltanto di euristiche soggettive che associano l'importanza in base a fattori tecnici. I motori di ricerca più evoluti o semantici, invece, analizzano il legame tra le parole e il topic ( argomento principale ) del testo, il lessico e la semantica delle frasi.
- Fattori esterni. I fattori esterni sono informazioni provenienti dall'esterno, rispetto alla risorsa, e possoo consistere in collegamenti ipertestuali in entrata ( backlink ) o in citazioni online. Sia i link in entrata che le citazioni risiedono su risorse esterne ( es. altri siti web ) rispetto alla risorsa da indicizzare ma, essendo indirizzate verso quest'ultima, ne rappresentano un segnale di popolarità o autorevolezza.
- RSS ( motori di ricerca ). Gli RSS (Really Simple Syndication) sono un altro metodo di indicizzazione. Un RSS è un fle XML nato per segnalare agli utenti gli ultimi aggironamenti di un sito. Quando il sito web pubblica un nuovo contenuto o modifica un contenuto già esistente, può segnalare l'indirizzo URL nel file RSS insieme al titolo, alla data e a una breve descrizione testuale. Gli RSS sono letti da appositi software client, installati sui computer degli utenti, e dalle piattaforme di aggregazione.Quando un file RSS viene aggiornato, l'autore può inviare un ping ( segnale digitale ) sia ai software client che alle piattaforme di aggregazione per segnalare la presenza del nuovo contenuto online. Gli utenti iscritti a seguire gli aggiornamenti del sito visualizzano in real time l'indirizzo URL della nuova risorsa sul software client. Lo stesso processo è utilizzato dai motori di ricerca, i quali possono ottenere dagli RSS l'informazione in tempo reale sulla pubblicazione delle nuove pagine e dei nuovi articoli.
- I limiti dell'indicizzazione. Ogni search engine fissa delle regole di indicizzazione e un elenco di caratteristiche delle risorse indicizzabili. Gli spider dei search engine sono software bot sviluppati per leggere esclusivamente il codice html delle pagine. Tutto ciò che è sviluppato con linguaggi differenti potrebbe non essere correttamente indicizzato. Ad esempio, le informazioni e i collegamenti ipertestuali realizzati in javascript o in Adobe Flash non sono letti dagli spider di prima generazione. Ultimamente i motori di ricerca hanno ampliato i contenuti indicizzabili anche a questi ultimi ( javascript, Flash, ecc. ). Gli spider limitano l'indicizzazione delle risorse anche in base al tipo di file ( estensione del file ). Generalmente, sono sempre consentiti i file Html (.html), Excel (.xls, .xlsx), Word (.doc, .docx), Power Point (.ppt, .pptx), Open Office, Rich Text Format (.rtf, .wri), file di testo (.txt), Portable Document Format (.pdf), i file XML, file immagini di tipo GIF, JPG, SVG, ecc. I tipi di file meno diffusi potrebbero non essere correttamente indicizzati.
Faq
- Quanto tempo impiega un motore di ricerca a indicizzare una pagina? Il processo di indicizzazione dura poche frazioni di secondi in termini computazionali. Tuttavia, dal momento della pubblicazione della risorsa a quello di indicizzazione possono passare giorni, settimane o mesi, a seconda della difficoltà con cui il motore di ricerca accede alla nuova risorsa e dalla posizione della risorsa nella coda di attesa dello spider.
- Come bloccare l'indicizzazione di un sito web? L'indicizzazione di un sito web può essere impedita impostando il parametro disallow nel campo user-agent del file robots.txt. Si tratta di un file situato nella root di un sito web. Gli spider dei search engine lo consultano per apprendere gli eventuali limiti alla scannerizzazione ( es. directory non indicizzabili ).
- Come bloccare l'indicizzazione di una pagina? Per impedire l'indicizzazione soltanto di alcune pagine html di un sito, lasciando indicizzabili tutte le altre, si inserisce il parametro noindex nel metatag robot delle pagine da non indicizzare. Il metatag robot è situato nella sezione head del documento html.



